

Research Progress
SIA Has Series of Research Papers Accepted by IEEE TIP
Recently, a series of research outcomes from the Machine Intelligence Research Group at the Robotics Laboratory, the Shenyang Institute of Automation (SIA) of the Chinese Academy of Sciences, have been formally published in IEEE Transactions on Image Processing (TIP), a leading journal in computer vision. The published works address continual video instance segmentation, medical CT image reconstruction, and unsupervised domain adaptive object detection.
Paper title: CRISP: Contrastive Residual Injection and Semantic Prompting for Continual Video Instance Segmentation
First author: Associate Researcher LIU Baichen
Corresponding author: Researcher HAN Zhi.
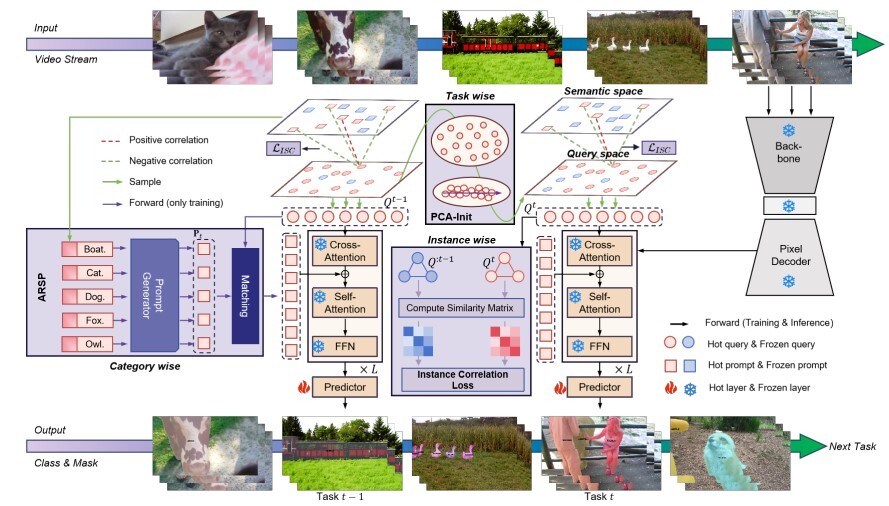
Contrastive residual learning and semantic prompting for video instance segmentation (Image by SIA)
To tackle the challenge of task-relevant objects being easily confused with the background in long-sequence dynamic scenes, the researchers investigated the dynamic decoupling mechanism of multimodal representations. Addressing the semantic drift problem in continual learning, they proposed a knowledge decoupling and feature injection model that spans three dimensions — instances, categories, and tasks. This model effectively suppresses catastrophic forgetting and semantic confusion in dynamic scenes, and maintains stable performance in scenarios such as similar object segmentation and high-speed object tracking.
Paper title: DVG-Diffusion: Dual-View Guided Diffusion Model for CT Reconstruction from X-Rays
First author: Ph.D. student XIE Xing
Corresponding authors: Researcher HAN Zhi and Assistant Professor QU Liangqiong.
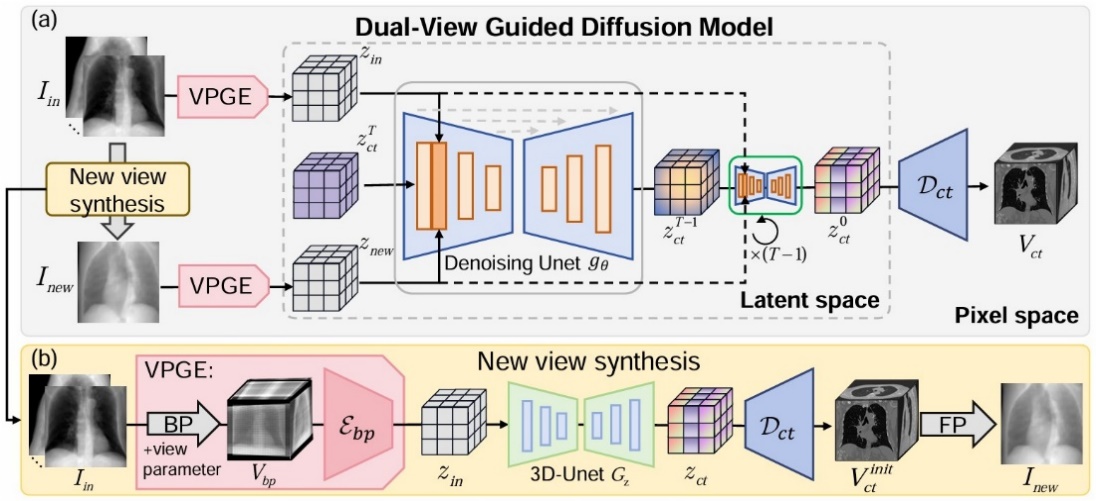
Dual-view guided diffusion model (Image by SIA)
To overcome the lack of spatial information and the ill-posedness of modality mapping when reconstructing 3D CT volumes from 2D X-ray images, the researchers proposed a dual-view guided diffusion model (DVG-Diffusion). This method leverages novel view synthesis and feature alignment mechanisms to reduce the difficulty of 2D-to-3D mapping. It extracts aligned features via a View Parameter Guided Encoder (VPGE), which then serve as conditioning to jointly guide a latent diffusion model for CT generation and refinement. As a result, the approach achieves an effective balance between high fidelity and perceptual quality in CT reconstruction.
Paper title: Unsupervised Domain Adaptive Object Detection via Semantic Consistency and Compactness Learning
First author: Ph.D. student LIU Yajing
Corresponding author: Researcher TIAN Jiandong.
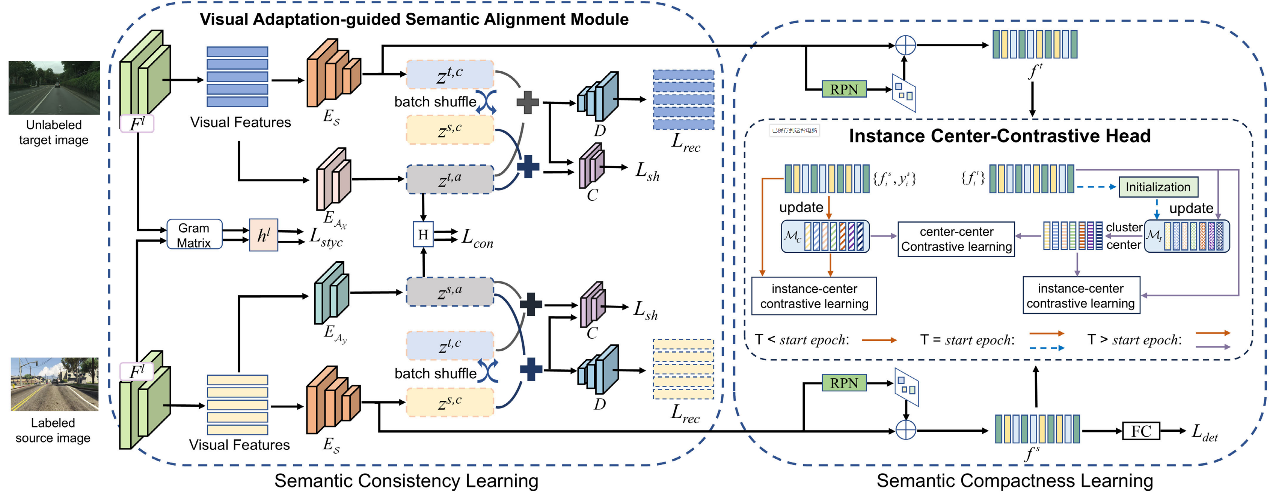
Semantic consistency and compactness learning network. (Image by SIA)
To address the issues of inefficient cross-domain feature style matching, insufficient decoupling of semantic features, and unreliable category compactness learning in unsupervised domain adaptive object detection, the researchers proposed a Semantic Consistency and Compactness Learning Network. Through visual-adaptively guided semantic alignment, the network achieves efficient and sufficient consistency learning. Furthermore, a plug-and-play instance-centric contrastive head was designed to tackle the reliability of compactness learning from three aspects: pseudo-label quality, sample storage and update strategy, and contrastive paradigm. This design simultaneously enhances both feature transferability and discriminability.
IEEE Transactions on Image Processing (TIP) is a journal in the field of image processing published by the Institute of Electrical and Electronics Engineers (IEEE). It is recognized as one of the three Class A journals in computer graphics and multimedia recommended by the China Computer Federation (CCF).
