

Research Progress
SIA Has Series of Research Papers Accepted by CVPR 2026
Recently, a series of researchpapers from the Machine Intelligence Research Group at the Robotics Laboratory of the Shenyang Institute of Automation(SIA), Chinese Academy of Sciences(CAS), have been officially accepted by CVPR 2026, a premier international academic conference in the field of computer vision. The accepted papers cover topics including polarization image processing, cross-modal transfer learning, 3D object detection, multi-agent collaborative tracking, and embodied intelligence manipulation.
Paper Title: Polarization State Tracing for Reflection Removal and Color-Consistent Reconstruction
First Author: WANG Dongyue (Ph.D. candidate)
Corresponding Author: Professor TIAN Jiandong

Color Glass Degradation and the Proposed Polarization State Tracking Model (Image by the research group)
Photographs taken through colored glass often suffer from severe color casts and ghosting. Addressing this phenomenon, the research team considered the selective absorption of glass and identified the previously overlooked issue of colored glass degradation. Based on polarization imaging theory, they modeled the transmission of polarized light throughout the entire process for the first time, establishing a Polarization State Tracing Model (PSTM). They also proposed a physics-based window-based ring-channel attention mechanism.
Paper Title: Decoupled and Reusable Adaptation for Efficient Cross-Modal Transfer
First Author: LIU Yajing (Ph.D. candidate)
Corresponding Author: Professor TIAN Jiandong
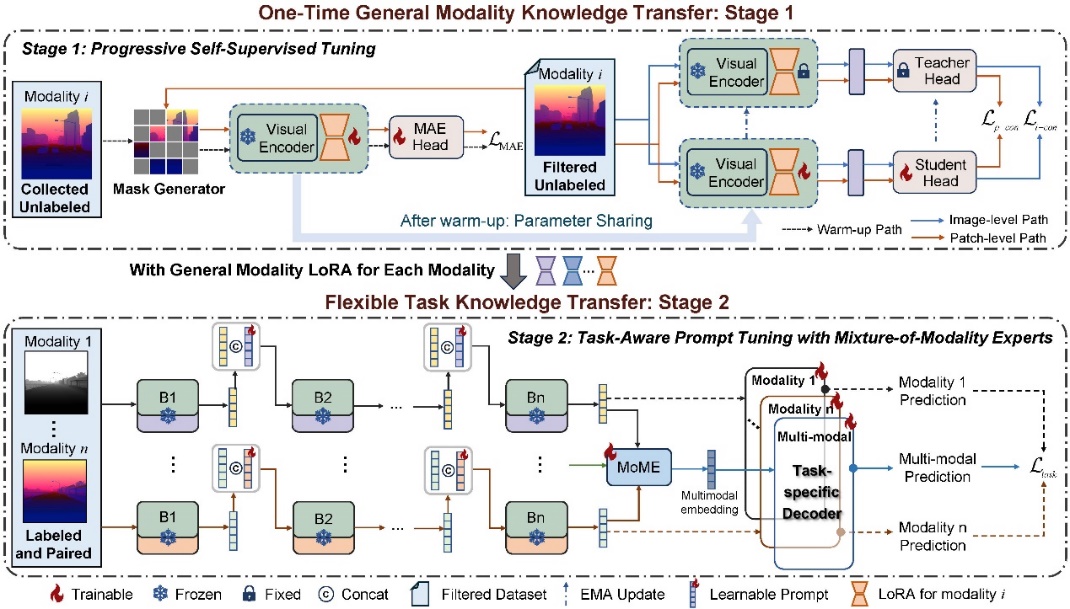
Efficient Cross-Modal Transfer Learning Framework (Image by the research group)
To address the issues of repetitive training and storage redundancy when switching tasks in cross-modal transfer, the team proposed an efficient cross-modal transfer framework. This framework decouples the transfer process into one-time universal modality knowledge transfer and flexible lightweight task knowledge transfer. Using unlabeled data for one-time pre-training, it generates task-reusable modality LoRAs, significantly improving data, computation, and storage efficiency for task adaptation in various downstream scenarios.
Paper Title: GMT: Effective Global Framework for Multi-Target Multi-Camera Tracking
First Author: ZHEN Yihao (Master's candidate)
Corresponding Author: Professor FAN Huijie
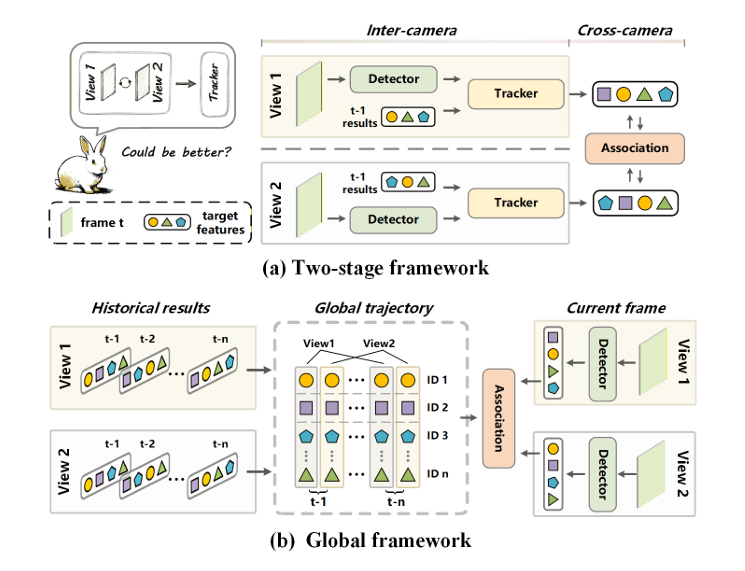
Global Multi-Agent Collaborative Tracking Framework (Image by the research group)
In response to the insufficient utilization of multi-view information in existing two-stage Multi-Target Multi-Camera (MCMT) tracking paradigms, the team proposed a Global MCMT Tracking Framework. By encoding local trajectories from different agents into global trajectories, the framework reformulates the tracking problem as a global trajectory-target matching problem, enabling direct utilization of multi-view information during the tracking process.
Paper Title: STUR3D: Spatio-Temporal Unified Representation Learning for 3D Object Detection
First Authors: FAN Huijie and HUANG Pengrui (jointly supervised student)
Corresponding Author: Associate Professor WANG Qiang
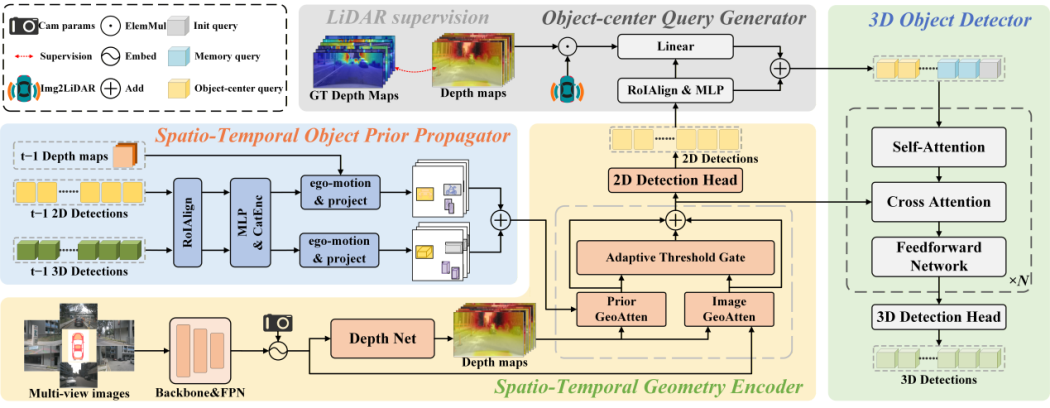
Spatio-Temporal Unified Representation Learning (Image by the research group)
To overcome the limitations of existing surround-view 3D detectors, which rely heavily on current-frame 2D information—leading to inconsistent spatio-temporal representations and easy loss of occluded objects—the team introduced the STUR3D framework for spatio-temporal unified representation learning. This framework innovatively incorporates a Spatio-Temporal Object Prior Propagation module, explicitly fusing historical detection results and injecting depth-aware geometric priors to advance spatio-temporal alignment between 2D and 3D perceptions. It significantly enhances detection stability and localization accuracy in dynamic and occluded scenes. On the nuScenes test set, STUR3D achieves state-of-the-art performance with 57.9% mAP and 64.6% NDS, effectively resolving performance bottlenecks in existing 2D-to-3D pipelines.
Paper Title: Continual Vision-Language Action Learning in Robotic Manipulation
First Authors: Dr. DONG Jiahua and WANG Xudong (Ph.D. candidate)
Corresponding Author: Professor HAN Zhi
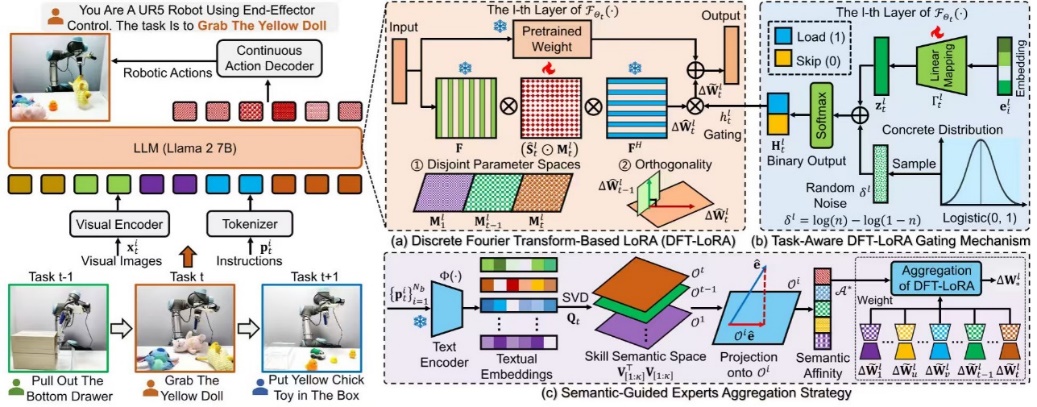
Vision-Language-Action Driven Continual Learning for Robotic Manipulation (Image by the research group)
Focusing on the core challenge of continual learning in robotic manipulation across multiple tasks, the team proposed a novel continual Vision-Language-Action (VLA) task learning framework named LISA. Within this framework, knowledge of sequential manipulation tasks is represented in the discrete Fourier space, enabling the robot to continuously acquire new manipulation skills while retaining existing capabilities. This approach effectively mitigates catastrophic forgetting during continual learning and significantly improves manipulation generalization.
CVPR is a world-renowned top-tier academic conference in the field of computer vision and is classified as a Category A conference by the China Computer Federation (CCF).
