In robotics, scene recognition enables robots to understand their surroundings and perform precise tasks. As artificial intelligence technologies see deeper integration across various industries, demands for higher accuracy and robustness in scene recognition are continuously increasing.
Recently, a research team at the Shenyang Institute of Automation (SIA), Chinese Academy of Sciences (CAS), proposed a novel scene recognition method called OSFA (Object-Level and Scene-Level Feature Aggregation), which integrates the CLIP multi-modal model. By dynamically aggregating object-level and scene-level features, the OSFA method significantly enhances classification accuracy and robustness in complex scenes.
Practical challenges such as lighting variations, object occlusion, viewpoint differences, and the diversity within similar scenes often make it difficult for recognition methods to extract stable and representative features. Furthermore, key technical hurdles include effectively integrating multiple semantic features in complex scenes while avoiding information redundancy or loss, and enhancing model generalization capabilities.
To address this, researchers first leveraged CLIP's visual features as prior information to extract local detail features highly relevant to the scene. Subsequently, CLIP's text encoder was used to generate category-specific textual semantic information. This guided the extraction of global semantic features from the image, which were then integrated via a scene-level cross-attention mechanism to form the final scene representation. To enhance model robustness, a multi-loss strategy was also introduced.
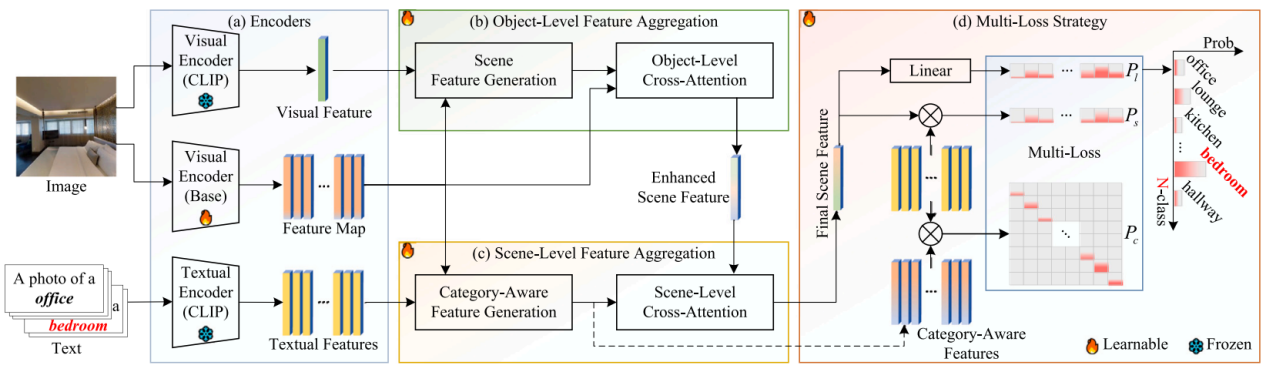
OSFA method framework (Image by the research group)
Research results demonstrate that this scene recognition method effectively aggregates features, notably improving classification accuracy and robustness in complex scenes. It can provide support for scene understanding and intelligent decision-making in fields like visual navigation and robotic applications, thereby enhancing perception and task execution efficiency.
The research, titled Object-Level and Scene-Level Feature Aggregation with CLIP for Scene Recognition, was published in the international journal Information Fusion. Qun Wang, a Ph.D. student at SIA, is the first author, and Researcher Feng Zhu of SIA is the corresponding author.
Link to paper: https://doi.org/10.1016/j.inffus.2025.103118